
n8n ai agents – Developing n8n ai agents is only 20% prompting; the other 80% is the infrastructure that keeps them from crashing under load. In 2026, as “Agentic Workflows” move from experiments to mission-critical operations, the gap between a hobbyist setup and a professional hosting for ai automation environment has never been wider.
Table of Contents
If your AI bot is slow, forgets conversations, or times out during complex tasks, you are likely missing one of these five infrastructure pillars. -> n8n ai agents
1. The RAM Trap: Moving Beyond Minimum Specs
Most teams look at the official n8n documentation and see “2GB RAM” as the baseline requirement. While that specification is perfectly adequate for standard data syncs or linear “If-This-Then-That” logic, it is a recipe for disaster when deploying production-grade n8n ai agents. In 2026, the complexity of “Agentic Workflows” has fundamentally shifted the resource landscape.

The Reality of AI Resource Consumption: Unlike traditional nodes, AI nodes in n8n are heavily resource-intensive because they don’t just “pass” data—they “reason” through it. When an agent chains multiple LLM calls (LangChain), parses high-density JSON objects from vector databases, or handles binary files like multi-page PDFs for RAG (Retrieval-Augmented Generation), memory usage spikes instantly. On a 2GB instance, these spikes trigger the Linux OOM (Out of Memory) Killer, which will terminate your n8n process mid-execution, leading to corrupted data and a frustrated user base.
The TezHost Edge: Scaling for Agentic Reliability
At TezHost, we have benchmarked hundreds of n8n ai agents in production environments. Our data shows that for a bot to handle concurrent user sessions without latency or crashes, a significant buffer is required.
- Recommended Standard: We recommend a minimum of 8GB RAM for any business-critical n8n ai agents.
- High-Performance Architecture: Our VPS plans are built on DDR5 RAM and NVMe storage, ensuring that even when your workflows hit peak complexity, the underlying hardware can handle the data throughput.
- Zero-Throttling Guarantee: Unlike shared cloud environments that throttle your CPU when AI nodes start “thinking,” our High-Performance VPS plans provide dedicated resources. This ensures your server doesn’t hit a bottleneck in the middle of a complex customer interaction, maintaining a seamless experience for your end-users.
2. NVMe Storage for Vector Memory and RAG
In 2026, the performance of n8n ai agents is defined by their “speed to thought.” When your agent utilizes Retrieval-Augmented Generation (RAG), it isn’t just generating text; it is performing a high-speed search across millions of data points to find the exact context it needs.

If your infrastructure relies on standard SSDs, you aren’t just losing seconds—you’re losing the “intelligence” of the interaction. Here is why the storage layer is the most overlooked bottleneck in n8n ai workflows.
The RAG Performance Gap: IOPS and Latency
When building n8n ai agents that use RAG, every user query triggers a complex chain of events. First, the query is converted into a vector embedding. Then, your agent must perform a “similarity search” against a vector database (like Pinecone, Qdrant, or pgvector). This process involves massive random read operations.
Standard SATA SSDs are architecturally limited by a single command queue, which creates a “bottleneck” during these intensive searches. This results in the dreaded 10-second “thinking” delay, where the user is left waiting for a response that should have been near-instant.
Why It Matters: Millisecond Precision
In a production-grade n8n ai workflow, fast read/write speeds are essential for injecting context into an AI’s prompt in milliseconds.
- Real-Time Context: To feel “human,” an AI agent must retrieve document chunks, parse metadata, and formulate a response in under two seconds.
- Concurrent Scaling: If you have 50 users querying your n8n ai agents simultaneously, a standard drive will choke under the parallel I/O requests. NVMe’s ability to handle 64,000 command queues ensures that every user gets a lightning-fast experience, regardless of server load.
The TezHost Edge: All-Flash NVMe Infrastructure
We don’t just host your workflows; we optimize them for the future of AI. Our nodes run on All-Flash NVMe storage, providing the raw throughput needed to fetch internal documentation and feed it to your AI agent without delay.
- 10x Faster Data Access: NVMe eliminates the translation layers that slow down traditional SSDs, allowing your vector database to communicate directly with the CPU via PCIe lanes.
- Zero-Lag Thinking: By reducing storage latency to microseconds, we ensure your n8n ai agents spend their time reasoning, not waiting for the disk to spin up data.
3. Persistent Chat Memory via PostgreSQL
In 2026, security is no longer an afterthought—it is the foundation of digital trust. When you rely on cloud-only automation tools, you are essentially handing over the “keys to your kingdom.” Your API credentials, proprietary business logic, and sensitive customer data reside on third-party servers that you do not own and cannot fully audit. A single breach at the provider level could expose every integration you’ve ever built.

By deploying secure automation workflows on a self hosted n8n instance via TezHost, you shift from a position of vulnerability to one of total defensive control.
1. Absolute Data Sovereignty
Data sovereignty is the principle that your digital information is subject to the laws and governance of the country where it is physically located. With self hosted n8n, your data never leaves the private perimeter of your VPS.
- Regulatory Compliance: This setup is essential for businesses that must comply with strict 2026 regulations like GDPR, HIPAA, or the latest AI safety mandates.
- Internal Auditability: Because you own the server, you can maintain full access logs and monitor every data packet, ensuring that sensitive information is never leaked to a third-party aggregator or used to train external AI models without your consent.
2. Invisible Infrastructure: VPN & Firewall Hardening
Standard cloud tools are “public-facing” by design, making them constant targets for automated bot attacks and credential stuffing. With a self hosted n8n setup on TezHost, you can effectively take your automation hub “off the grid.”
- Network Segmentation: By placing your instance behind a private VPN (like WireGuard or OpenConnect) or an IP whitelist, the n8n editor becomes invisible to the public internet.
- Firewall Logic: You can configure your VPS firewall to allow only specific “east-west” traffic—meaning your n8n instance can talk to your internal database, but no one from the outside can talk to your n8n instance. This drastically reduces your attack surface compared to a multi-tenant cloud environment.
3. Ownership of Encryption Keys
In a managed cloud environment, the provider typically manages the encryption keys. This means they—and potentially any government agency with a subpoena—could technically access your stored credentials.
- The Self-Hosted Advantage: In a self hosted n8n environment, you define the
N8N_ENCRYPTION_KEYenvironment variable. This key is used to salt and hash your passwords and encrypt your third-party API tokens at rest. - Key Persistence: Because you control this key, you can rotate it according to your company’s security policy and ensure that even if a raw database backup were stolen, the credentials within it would remain an unreadable cipher.
The Fatal Flaw of Simple Memory in Production
A common mistake in early AI development is relying on n8n’s “Simple Memory” node for production-level n8n ai agents. Simple memory is essentially short-term, volatile storage that lives within the execution’s temporary RAM.
If your server restarts for a security patch, or if you simply hit “save” on a workflow update, that temporary memory is instantly purged. For the end user, this is a disastrous experience because n8n ai agents suddenly “forget” who they are, their previous context, and the specific problem they were trying to solve. In a professional 2026 business environment, this lack of continuity breaks user trust and destroys the core utility of the bot.
To maintain a high-quality user experience, n8n ai agents require persistent database integration to ensure every conversation remains intact regardless of server reboots. Without this structural backbone, your n8n ai agents will fail to provide the reliable, long-term memory that modern customers expect from intelligent automation.
Why Your Hosting Needs a Dedicated PostgreSQL Backend
To build truly resilient n8n ai agents, your infrastructure must include a persistent database. This is why a dedicated PostgreSQL integration is a non-negotiable requirement for professional hosting for ai automation.
By connecting your AI agent to a PostgreSQL instance, chat histories are written to a permanent disk. This allows for:
- Session Persistence: Users can return days or weeks later and pick up exactly where they left off.
- Complex Reasoning: Agents can query thousands of previous interactions to find patterns and provide personalized answers.
- Cross-Workflow Context: Different automations can share the same memory pool, creating a unified “brain” for your entire company.
The TezHost Edge: Zero-Config Persistence
Setting up a production-grade database usually involves complex Docker networking and credential management. However, the TezHost One-Click n8n Installer simplifies this entire process by automatically configuring a robust, pre-tuned PostgreSQL backend for you.
This means your n8n ai agents are born with long-term “brain” stability. Out of the box, your instance is ready to handle thousands of concurrent sessions with encrypted, persistent memory, ensuring your AI never suffers from “deployment amnesia.”
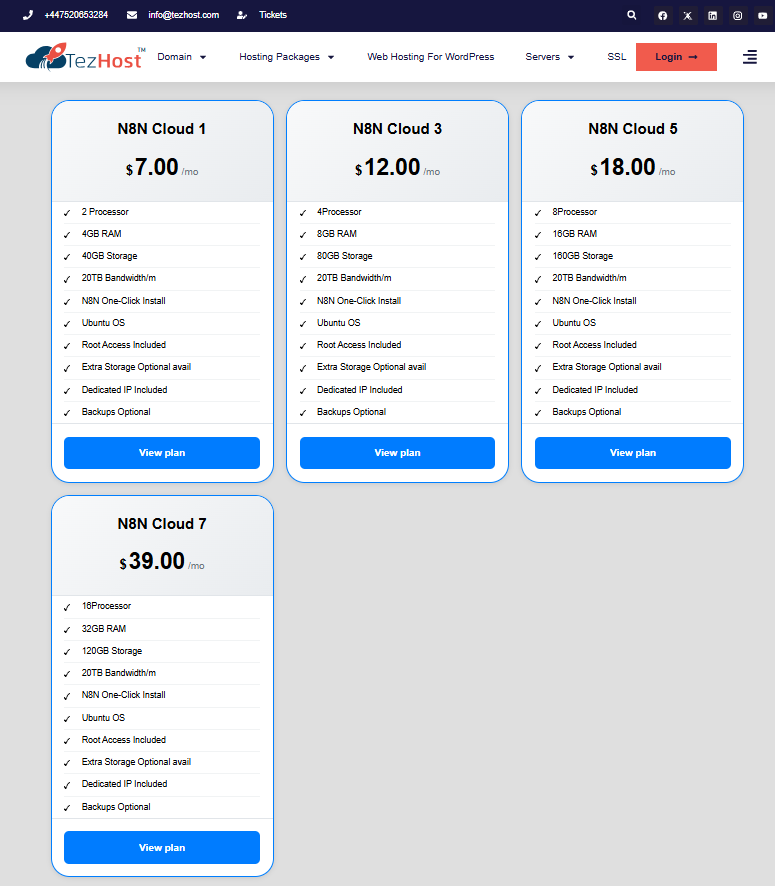
4. Queue Mode and Multi-Instance Scaling
What happens when 100 users trigger your n8n ai agents at the same time? In a standard “Single Mode” setup, n8n attempts to handle the editor UI, incoming webhooks, and heavy AI logic all within a single process. When a surge of requests hits, this creates a technical “traffic jam.” The CPU spikes to 100%, causing the server to throttle and making your dashboard completely unresponsive. For a business, this means dropped leads and timed-out customer interactions. To prevent this, professional n8n ai workflows must be shifted into Queue Mode, which decouples the “request intake” from the “actual processing.”

The Missing Link: Distributed Architecture with Redis
Moving to a high-performance n8n ai agents environment requires a distributed architecture. The “Missing Link” here is the introduction of Redis and Worker Nodes. In this setup, your main n8n instance acts as a dispatcher: it receives the trigger and immediately hands the job off to a Redis-backed queue. Independent Worker Instances then pull these jobs from the queue and execute the heavy LLM chains in parallel. This ensures that even if you have 50 agents running complex reasoning tasks simultaneously, your primary editor remains fast and your webhooks never miss a beat.
The TezHost Edge: Dedicated CPU Cycles for AI
The effectiveness of this distributed setup depends entirely on the underlying hardware. This is where The TezHost Edge becomes your competitive advantage. While shared hosting or low-tier “burstable” instances might throttle your CPU precisely when your n8n ai agents need it most, a TezHost VPS provides dedicated, non-shared resources. This means you have consistent, high-clock-speed CPU cycles available to power your Redis message broker and multiple worker processes. By hosting on TezHost, you eliminate the “noisy neighbor” effect, ensuring your AI dashboard never freezes, regardless of how many concurrent users are interacting with your bots.
5. Data Sovereignty and API Security
In 2026, sending sensitive company data through a public cloud automation tool is no longer just a risk—it’s a compliance nightmare. As n8n ai agents become more deeply integrated into corporate ecosystems, they handle everything from internal financial reports to protected customer PII (Personally Identifiable Information). If you rely on shared cloud environments, your proprietary logic and sensitive API keys are stored on third-party servers, creating a “black box” that few IT departments can verify. For industries like FinTech, Healthcare, or Legal, this lack of transparency is an immediate deal-breaker.

The Missing Link: Private Firewalls and Vector Embedding Security
The core requirement for professional n8n ai agents is a self-hosted environment where your data never leaves your control. In a modern AI workflow, your “Vector Embeddings”—the digital representations of your company’s private knowledge base—are just as sensitive as your passwords. By hosting on a private server, you ensure that your vector databases and API credentials stay behind a custom-configured private firewall. This prevents “data leakage,” where your proprietary information could inadvertently be used to train public LLMs, a common fear for businesses deploying n8n ai agents in 2026.
The TezHost Edge: Your Private “Walled Garden”
Hosting on TezHost provides the “Walled Garden” infrastructure that modern AI requires. Unlike multi-tenant cloud platforms, a TezHost VPS gives you total sovereignty over the software stack. You control the encryption keys used to secure your credentials and the specific network access rules that govern how your n8n ai agents communicate with the outside world. This setup ensures your AI bots are as secure as they are smart, providing a high-performance, isolated environment where you can scale your n8n ai agents without ever compromising on data privacy or regulatory compliance.
Coclusion
In 2026, the shift toward n8n ai agents marks the end of “brittle” automation and the beginning of “intelligent” operations. Traditional tools that simply connect App A to App B are being replaced by autonomous systems that can reason, plan, and execute multi-step tasks. However, as we’ve explored, the strength of these agents is entirely dependent on the infrastructure they sit upon.
The Path Forward for Your AI Infrastructure
Building production-ready n8n ai agents requires a move away from shared, restricted cloud environments. To truly harness the power of agentic workflows, businesses must prioritize:
- Performance Scaling: Moving beyond minimum RAM requirements to high-performance VPS environments that can handle the heavy computational load of LLM orchestration.
- Operational Reliability: Implementing Queue Mode with Redis to ensure your agents can handle hundreds of concurrent requests without service degradation.
- Uncompromising Security: Utilizing a “Walled Garden” approach on a TezHost VPS to keep your vector embeddings, API keys, and sensitive customer data within your own private perimeter.
Final Verdict: Ownership is the Ultimate Advantage
The decision to go with a self hosted n8n setup on TezHost is more than just a cost-saving measure—it is a strategic investment in data sovereignty and unlimited scalability. While cloud platforms like Zapier or n8n Cloud offer a quick start, only a self-hosted VPS provides the “zero-ceiling” environment needed to build the most advanced n8n ai workflows of 2026.
By choosing TezHost, you are not just hosting a tool; you are building a private, secure, and lightning-fast “brain” for your business.
Ready to launch? Deploy your AI-optimized VPS on TezHost today and start building the future of autonomous business.
TezHost Official Website: TezHost is a leading web hosting provider offering high-performance solutions, including domain registration, NVMe-backed web hosting, and dedicated servers with 24/7 expert support.
n8n Hosting Packages: TezHost provides specialized Self-Hosted n8n VPS plans featuring a one-click auto-installer, allowing you to run unlimited automation workflows with total data sovereignty and cost predictability.
PostgreSQL Web Hosting: Their Managed PostgreSQL Hosting delivers an optimized environment for complex data-driven applications, complete with high-speed query execution, robust security, and seamless developer tools.


